Data Pipeline
Parse.ly’s Data Pipeline (DPL) provides you with a fast and easy way to build in-house analytics atop flexible, clean, accessible, and real-time user interaction data.
Before you begin
Ensure that you’ve purchased the Parse.ly Data Pipeline by reviewing your contract. Contact your Relationship Manager with questions.
Watch the Data Pipeline overview video
What is user interaction data?
Every time your users, customers, or prospects interact with your business online, they generate user interaction data.
This includes when they visit your website; read your content; use your mobile app; view your ad; sign up for a newsletter; buy a product/service; or do anything else associated with your business from a connected device. But this kind of data has traditionally been difficult to collect and access.
The kind of interactions users have with your business usually center around two things: users (visitors) and content (URLs). And the interactions can vary from the surface-level (such as content views) to the very detailed (such as precise number of seconds spent reading/watching a piece of content).
Parse.ly measures all of this, providing a deep and detailed understanding of both visitors and the content on your site or in your apps/products. Parse.ly also provides robust infrastructure instrumenting your own user interactions, otherwise known as custom events.
Why do I need a Data Pipeline?
Although you could spend resources to develop expensive infrastructure from scratch, Parse.ly is ready to provide you with a cloud analytics pipeline. And Parse.ly has already scaled it to support hundreds of the web’s largest sites and it processes billions of monthly interactions.
Using Parse.ly Data Pipeline, you can turn any website or mobile app into a data stream of rich user interaction data — and you can do so in minutes, not months.
What makes Parse.ly different?
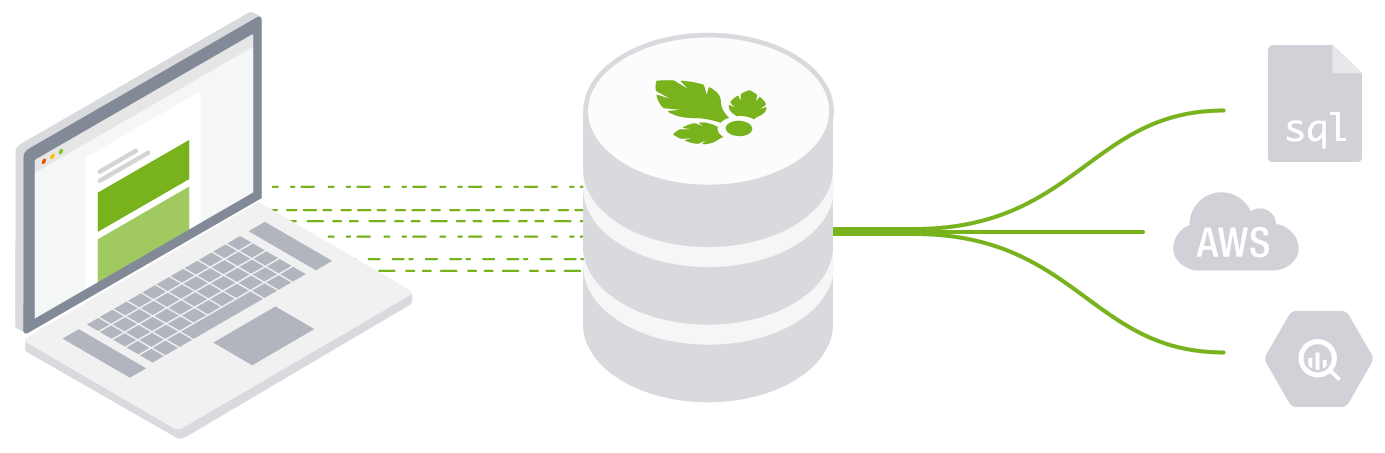
- You own the data. Parse.ly’s Data Pipeline swiftly delivers 100% of your raw, unsampled data without rollups. Parse.ly captures and securely stores every single event from your users, sites, and apps. Parse.ly provides an elastic data store for complete historical retention. Parse.ly provides raw event data for unrestricted analysis. Every interaction is yours to manipulate, analyze, join with other sources, or transfer.
- Access via standard AWS APIs. You have the option of Amazon S3 for historical data and Amazon Kinesis Streams for real-time data. Client libraries exist for all popular programming languages and analysis frameworks. Access to your data is possible even from local development machines or other cloud hosting providers.
- Proven reliability. Parse.ly’s technology supports over 100,000 users via the real-time content analytics dashboard.
- Scale in minutes, not months. By providing the JavaScript tracker through a global CDN and DNS, Parse.ly’s infrastructure assures prompt data delivery and low latency.
- Integration is a breeze. Parse.ly’s data formats are compatible with Python, R, Spark, Redshift, BigQuery, and more. Parse.ly also provides standard schemas for data use in tools like Looker, Periscope, and Tableau.
- Cost-effective. Parse.ly’s large-scale analytics service allows significant discounts on the Data Pipeline service. Customers have reported significant cost savings and risk reductions associated with development.
- Fast. Parse.ly measures end-to-end delivery times in seconds. Parse.ly captures every single event and stores it securely and durably. From there, you also get an elastic data store for full historical retention, stored in 15-minute chunks of compressed JSON data.
The fast path to custom analytics
In short, Parse.ly’s Data Pipeline gets you to your data insights faster. Don’t deal with the drudgery of building a real-time data collection and delivery pipeline. Don’t bang your head against some legacy vendor’s antiquated schemas and unclean data sources.
Instead, get on the fast path to custom analytics.
Next steps
Further reading:
Help from our team:
- Already a Parse.ly customer? Simply open a ticket, and Parse.ly Support will be in touch with how to get you the raw data you’ve been looking for.
- Not a Parse.ly customer? No worries! Fill out this form and someone will be in touch shortly.
Last updated: November 26, 2025