Data Pipeline use cases
Parse.ly’s Data Pipeline is useful to a number of roles, including CTOs, CIOs, Data Scientists, Data Engineers, BI Analysts, SQL Analysts, and anyone else who derives value from a unified real-time stream of user, web, and mobile engagement data.
For Business Intelligence Teams
BI teams need to understand their users and business at a fine-grained level. This can be helpful for corporate/executive reporting functions, or to guide other departments like product, audience development, content, or marketing.
Only raw data can enable ad-hoc reporting, and Parse.ly’s Data Pipeline is a reliable and foundational piece of infrastructure to get you there.
As an example, customers often integrate our pipeline with their own ETL before dumping the data in Amazon Redshift or BigQuery. They then use a tool like Looker to provide data exploration and dashboard interfaces for their teams.
Below is an example dashboard built using Parse.ly’s Looker Data App which is itself based on our standard Parse.ly event schema. Using the Looker Data App (built with LookML), you can recreate many of the kinds of queries that power Parse.ly’s real-time audience dashboards, but within Looker itself and with full control/customizability.
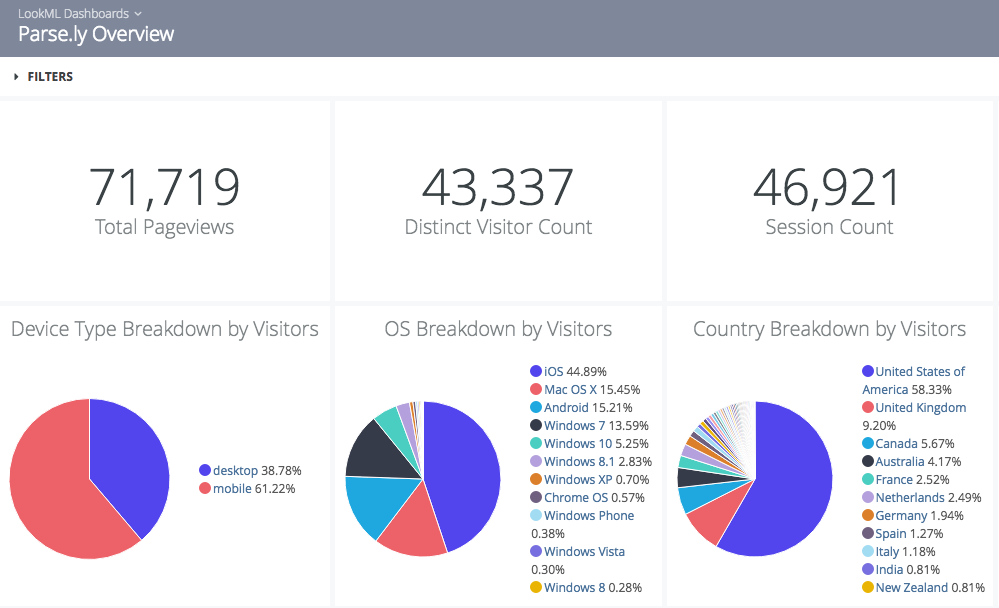
For SQL Experts
The world’s most popular relational database engines, like MySQL and Postgres, used to be a poor fit for raw event analytics data, simply due to scale. But in the last few years, a number of cloud SQL offerings have emerged that make analyzing terabytes of raw event data not only possible, but easy.
Amazon Redshift and Google BigQuery are two market leaders, both of which have been tested to be fully compatible with Parse.ly’s Data Pipeline. Integration with these systems is often no more than a few lines of code. This is because Parse.ly’s data formats have been specifically optimized to be cleanly integrated by their bulk loading and stream loading tools.
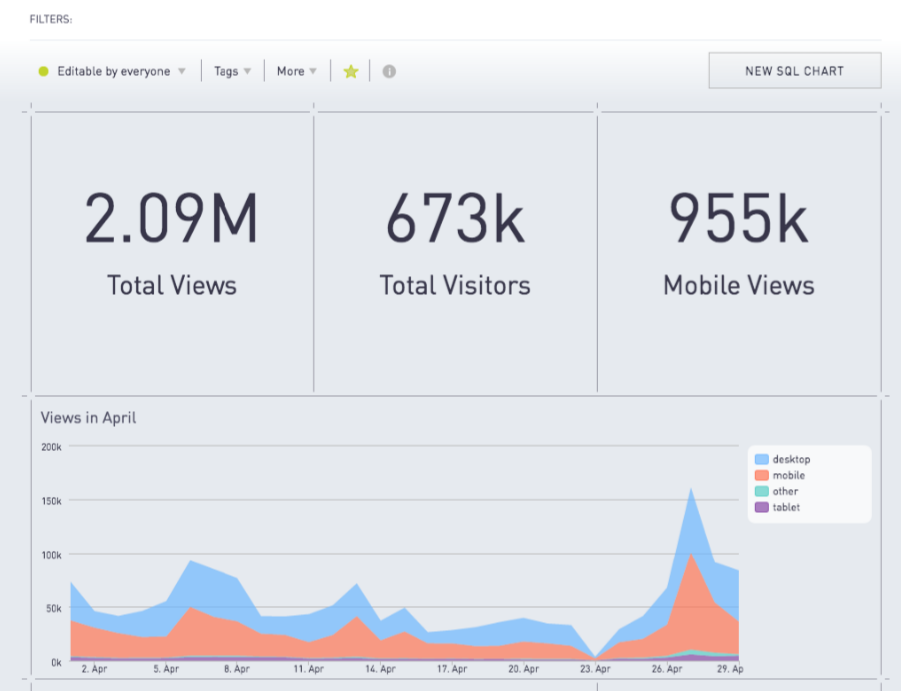
If you have many SQL experts on your team, you can use a tool like Periscope to query your raw data. Dashboard components are built up from a raw SQL query run against Parse.ly events.
Here is an example Periscope dashboard built from Parse.ly’s raw data schema.
For Data Scientists
Data Science is the combination of data analysis, statistics, and programming. With Parse.ly’s Data Pipeline, you can use interactive data exploration environments such as:
- Jupyter, for Python users
- R Studio, for R users
There are also hosted environments that work well, such as:
- Databricks Community Edition, for Scala/Python/R users
- Mode Analytics, for Python/SQL users
Here is an example Mode Analytics SQL sheet running a query against Parse.ly raw data that has been synced up to BigQuery.
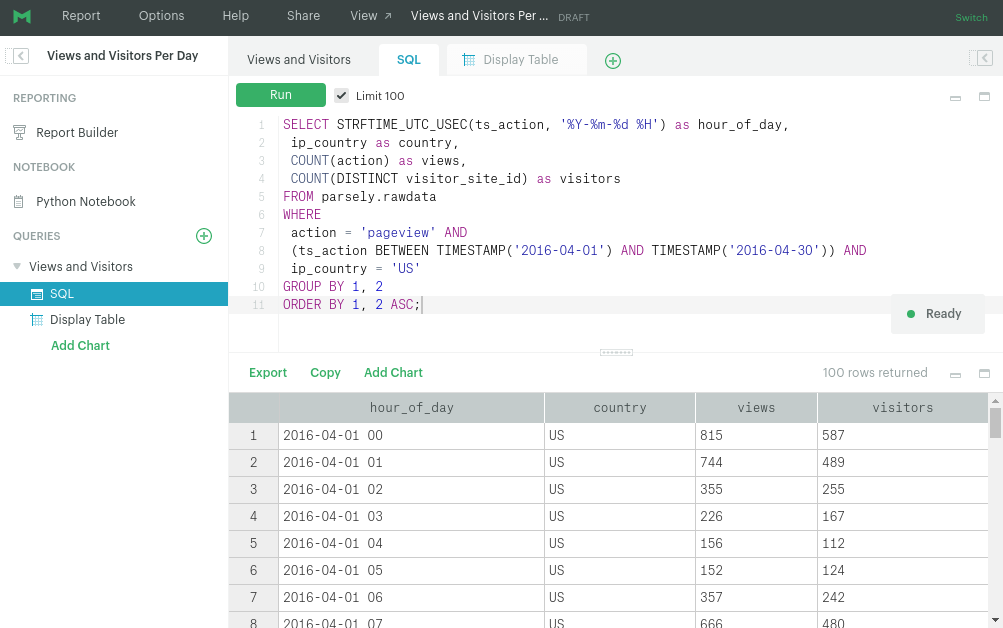
For Data Engineers
Parse.ly data can provide a great starting point for leveraging open source “big data” technologies, such as:
- Map/Reduce: Hadoop, Pig, HDFS
- In-Memory: Spark, SparkSQL
- Streaming: Storm, Kafka
- Log Analytics: Hive, HBase, Cassandra
- Document Stores: MongoDB, Elasticsearch
- MPP Databases: PrestoDB, Drill, Druid, Impala
Data Pipeline is also a great fit for public clouds and their associated analytics technologies, such as:
- Amazon’s: EMR and Redshift
- Google’s: Dataproc and BigQuery
- Microsoft’s: Azure Spark and HDInsight
For Product Teams
Even if your organization doesn’t have a formal analytics, data science, or business intelligence practice, you may find raw analytics data to be one of the best ways to evolve your product. A reliable Data Pipeline can also create virtuous product feedback loops, such as:
- personalization
- alerting
- internal usage dashboards
- loyal user targeting
- email and notifications
Next Steps
Further reading:
Help from our team:
- Are you a BI Analyst? Set up a demo with our team to see Parse.ly data with our pre-built Looker Data App; to see JSON and SQL data samples; and to showcase interactive dashboarding environments.
- Are you a SQL Expert? Get a walk-through from a Parse.ly analyst, showing you standard SQL schemas for Redshift and BigQuery, and some example SQL queries against Parse.ly’s raw data in a Periscope dashboard.
- Are you a Data Scientist or Engineer? Meet one of our engineers, who can walk you through bulk and streaming loads of Parse.ly data in common open source or data exploration environments.
Last updated: June 03, 2024