What is a ‘premature pixel’?
A ‘premature pixel’ refers to a scenario in which the Parse.ly Crawler is unable to access a webpage and its metadata when data collection begins. This occurs after the initial pageview event is received and surfaced for that same page. Most commonly, the cause for this is derived from a publisher previewing a page before it is live. Fortunately, this issue usually resolves itself within a few days after our nightly, automated rebuilds are complete. No data is lost– it just needs to be re-indexed accordingly.
Let’s take a closer look…
The primary indicator of a ‘premature pixel’ is two instances of the same page in the dashboard. Here you’ll usually find one of those instances appearing in the dashboard without metadata, in the ‘Non-posts’ section. This behavior is expected considering the Crawler did not initially ingest metadata since the page was inaccessible. Here’s an example of how a page with a ‘premature pixel’ appears in the dashboard:
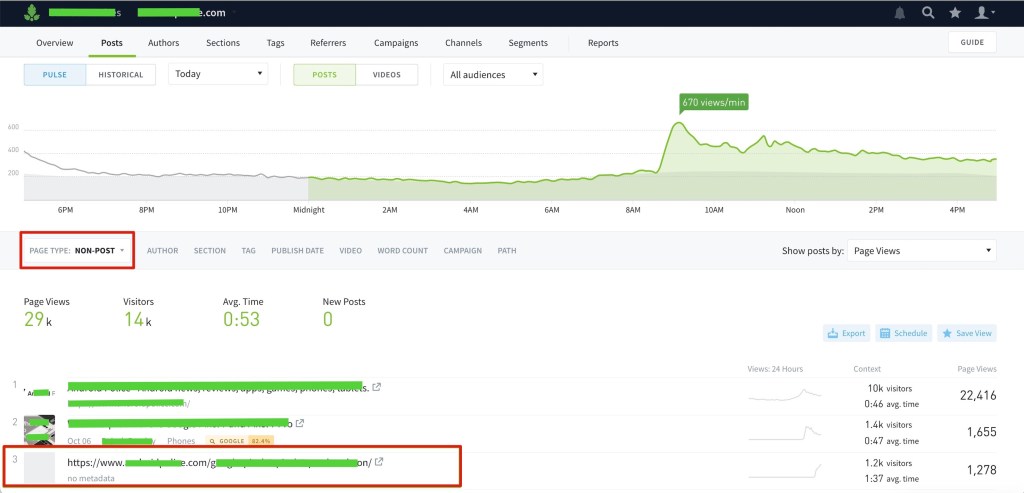
In this example, we see three pieces of content. The top two are valid index or “Non-post” pages. The third piece of content appears in the non-posts list because it has no metadata. However, if the URL was not redacted, you’d see that this piece of content more closely resembles Parse.ly’s definition of a “Post”.
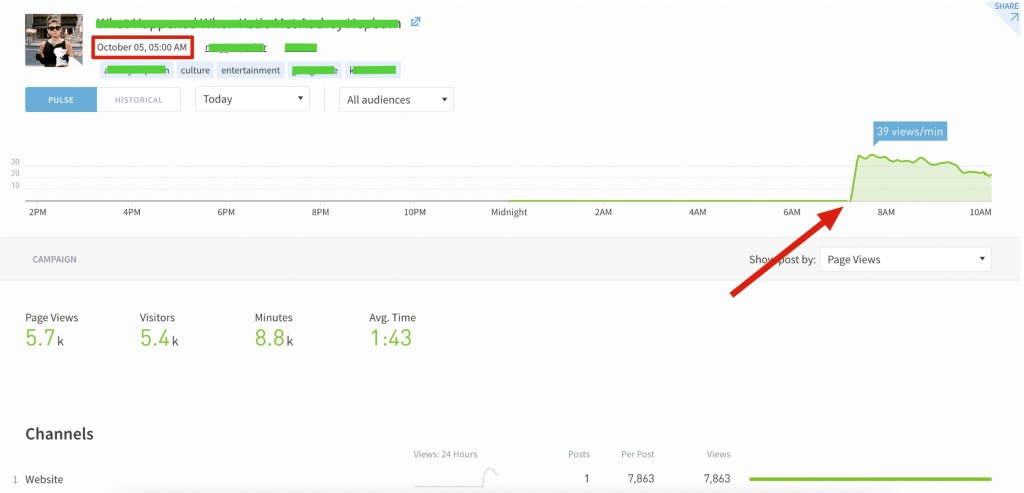
The other corresponding instance of this page in the dashboard is the one you’ll likely notice first, as it includes the metadata. This is the version that the Crawler successfully accessed and scraped. Note in the example below that the publication time and the first stream of pageviews do not match. The publication time is 5:00 AM, yet the first pixel received and tracked in the graph is around 7:00 AM. This is the most telling symptom that this page suffers from a ‘premature pixel’ issue.
Next steps
The good news here is that Parse.ly has been collecting data all the while, and our automated recrawl and rebuild processes for newly published content ensure the resolution of the issue. If our crawler is initially unable to access a given page, it will re-attempt to do so at an interval of 1m, 5m, 25m, 2h5m, 10h25m, 2d4h5m. It is usually in one of these time windows that the Parse.ly Crawler will finally have the appropriate access and ingest the necessary metadata.
It’s important to note that if this is a recurring issue it’s imperative to ensure that the Parse.ly tracker is not present on preview pages or any other pages that aren’t live/publicly accessible.
WordPress plugin implementations
If you are setting the JavaScript tracker with the Parse.ly plugin for WordPress (if Disable JavaScript is set to “No” in the plugin settings), there’s a quick solution that eliminates the ‘premature pixel’ issue. Choosing “No” for the “Tracked Logged-in Users” option on the plugin settings page will ensure that the Parse.ly tracker won’t be set on previewed web pages (and all other pages).

Google Tag Manager implementations
If you have implemented the Parse.ly tracker using Google Tag Manager (GTM)—using the Parse.ly tag template or otherwise—you can prevent the Parse.ly tracker from loading for WordPress logged-in users by creating a trigger exception.
- Create a DOM Element variable with the following:
- Selection Method: CSS Selector
- Element Selector:
body.logged-in - Attribute Name:
class
- Create a Page View trigger (see note below) with the following:
- This trigger fires on: Some Page Views
- Condition: {{variable from step 1}} | does not equal |
null
- Add the trigger from step two as an exception trigger on your Parse.ly tracker tag.
Note on the exception trigger
The exception trigger must be the same type as your firing trigger. The above example assumes the Parse.ly tracker tag has a Page View firing trigger. If the firing trigger is another type (such as DOM Ready or Initialization), choose the matching trigger type in step two.
Last updated: June 05, 2025