How to interpret Headline Testing results
Parse.ly’s Headline Testing engine relies on multi-armed bandit (MAB) algorithms and Bayesian statistics.
During the test, Parse.ly uses a multi-armed bandit to dynamically allocate the traffic to headlines. At the start, it makes no assumptions about their performance. As traffic starts coming, the likelihood of each headline being the best gets recalculated regularly. The system uses these calculations to update the traffic allocation, enabling the system to prioritize the winning headlines even before the test is over.
Once the test is over, Parse.ly uses Bayesian modeling to predict the future performance of each variant. These predictions take the form of probability distributions for the click-through rate for each headline. The improved algorithms that Parse.ly’s introducing are focused on simplifying that information and making it actionable. Chiefly, all test results will now include a confidence grade based on the calculated probability that the given headline will have the best click-through rate in the future (a.k.a. win chance). It should be understood as the degree of certainty.
Not every headline test ends with a statistically confident winner, but that doesn’t mean the test failed. Valuable insights can still emerge, especially when looking at the Help Chance metric. This helps you choose headlines that are likely better than your control, even when the system isn’t confident enough to declare a single clear winner.
To communicate the win chance and other key information, Parse.ly has refined our results dashboard with additional features focused on supporting decision-making.
Winner Badge

The winner badge shows your winning headline with its confidence grade. In the popover box for the grade, you can see the win chance for the winner on the first line. Additionally, you can see the chance of this variant beating the control, aka the help chance. If the help chance is high, then accepting that variant over the control will not lead to worse conversions, even if the variant is not the optimal choice according to the win chance.
Performance Metrics
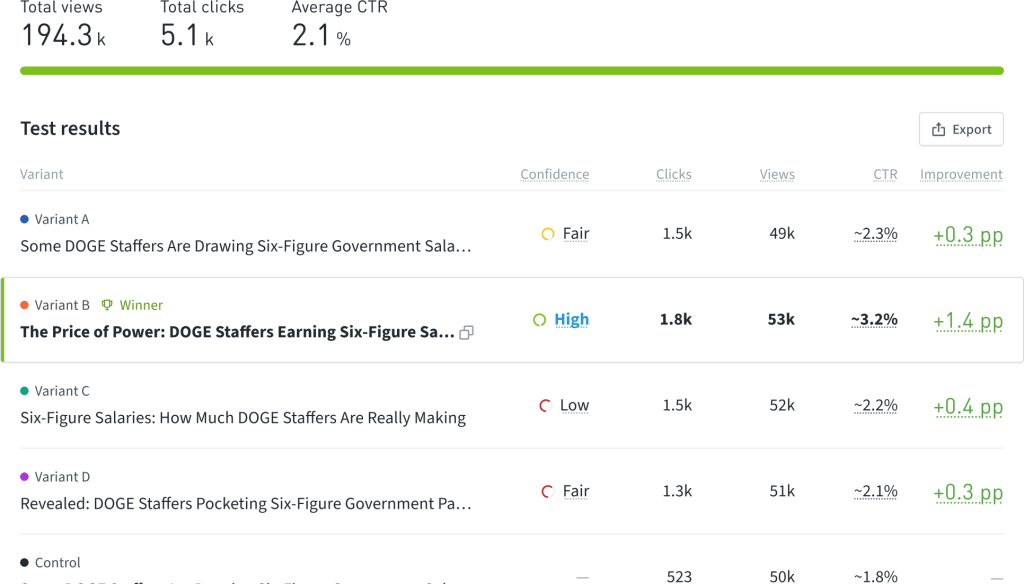
Several performance metrics are displayed:
- Confidence grade: How certain Parse.ly is about this variant’s performance.
- Total clicks: How many visitors clicked on the headline.
- Total impressions: How many times the headline was shown (impressions).
- Click-through rate (CTR): The percentage of people who clicked.
- Improvement: Absolute CTR improvement over control, in percentage points.
In addition to the confidence grades having the same popover as in the winner badge, Parse.ly has refined the CTR and the improvement metrics with credibility popovers. They contain more detailed information about the predicted future performance.
Evolution Chart
The bottom graph shows how each headline performed over time during your test. This helps you see if performance was consistent or if there were any unusual spikes or drops that may have influenced your results.
Reading test results
To help you make use of these new tools, Parse.ly uses a system of confidence grades for all headlines.
- High: The headline has a win chance of at least 95%. These are your strongest results, and you should feel comfortable implementing them right away.
- Fair: The headline has a win chance between 70 and 95%. There’s a little more uncertainty here, and some discretion is advised. You should compare the win chance to your editorial judgment.
- Low: The headline has a win chance between 55 and 70%. These results can be quite uncertain, only suggest, and it’s valuable to review both the win chance and the help chance.
- Insufficient: The headline has a win chance below 55%. These are the results that Parse.ly considers unreliable. Review the Help Chance – which tells you if using the headline will be an improvement over the control variant, even if that may not be the best improvement possible. if your editorial instincts lead you here, the numbers remain valid.
With these grades explained, a test can have 3 outcomes:
- Winner: A winner has been identified with a sufficient confidence grade (high, fair, or low).
- No clear winner: We couldn’t determine a clear winner, but some headlines may have shown strong indications of better performance (see Help Chance)
- Not enough data: The test did not receive enough traffic to make for a workable evaluation. This will happen whenever the test gets fewer than 200 impressions or no clicks.
As mentioned above, the data for tests with no clear winner is valid. If your judgment tells you that one of the headlines should connect with the audience, Parse.ly recommends that you review the numbers and make the best practical use of them.
Should you wish to remediate a test without a clear winner or without enough data, you should run it again and collect more traffic per headline. If you’re here, you’ll likely want to run the test for longer than before, and it might be worthwhile to see if you can reduce the number of headlines or review the content placement on the site.
Best practices
If a headline shows a high Help Chance but low Win Chance, it is still likely to outperform your original. Consider using it if it aligns with your editorial goals. You’re still improving, even if we can’t say it’s the best possible option.
- Set the control variant to your most preferred headline.
- Seek to concentrate traffic—fewer headlines, longer experiments.
- Use the win chance for the easy decisions, but bring in the help chance for the tough ones.
- Compare the improvement in CTR to the improvement in the editorial sense. It’s fine to ignore a 99% winning headline that only adds 0.1 percentage point to the CTR if you don’t love it.
- The goal of this exercise is not to dictate winners, but to support data-driven decisions.
Last updated: November 06, 2025