Integration of OpenAI in Content Intelligence
Parse.ly Content Intelligence (PCI) enhances editorial workflows by providing performance statistics and AI-assisted tools. This post will focus on the latter. PCI’s AI components rely on generative pre-trained transformer models hosted by OpenAI. As of this writing, we’re using OpenAI’s GPT-4o series. This model applies advanced language understanding to Title Suggestions, Smart Linking, Excerpt Suggestions, and Engagement Boost.
AI-tooling access
The AI components of PCI are optional. We will only add them when your team asks that they be added.
Gaining access to PCI requires the following:
- Enabling the wp-parsely plugin.
- Configuring the plugin with a Site ID and API Secret — this enables performance statistics.
- An API Secret is available to Parse.ly customers who purchase API access.
- We also provide an API Secret for customers hosted by Automattic (WordPress VIP, Newspack, Pressable, etc.) to power the plugin.
- Providing Opt-in consent — this tasks Parse.ly Support to enable AI-assisted tools.
- Admins can then restrict AI access at the user-role level within the wp-parsely settings.
- AI-assisted tooling is available to Automattic-hosted customers.
How Parse.ly Content Intelligence uses OpenAI services
At its core, the PCI backend follows a standard retrieval-augmented generation (RAG) workflow to fulfill user requests as more fully explained in this diagram from our RAG announcement:
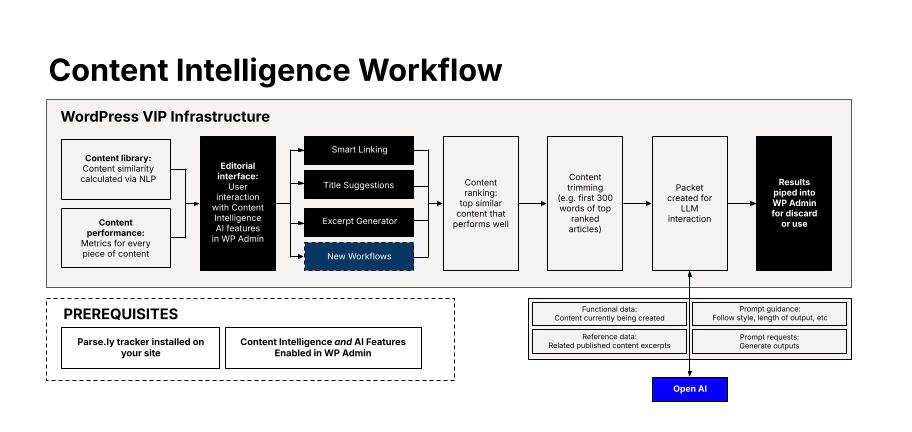
For your content library, we maintain a database of your published content’s vector representations (embeddings). We calculate these embeddings entirely within our infrastructure, using self-hosted open-source machine learning models.
Initial indexing process
For customers who recently opted into the AI-powered PCI features, the initial indexing process may take up to 24 hours to complete and make their content available for augmentation. Conversely, customers opting out of the AI-powered feature(s) will see these embeddings for their content purged within 24 hours of processing their request.
Gathering data through the plugin
When end users make requests through our tools, such as Title Suggestions, the plugin backend will perform the following:
- Scan the embeddings database for related content, sorting the results according to the task parameters (by relevance, traffic, or a combination thereof) and selecting a handful of best matches.
- Pre-process these references, for example, by trimming the excess content. Our experience shows that a few hundred words of reference material is plenty for augmentation.
- Augment the functional data, such as the full text of the article missing a headline, with the reference data.
Processing with OpenAI
Once we finish gathering this data, we use the resulting data parcel to generate the text results — Title Suggestions in the above example — via the enterprise OpenAI API. This is the final step of our workflow, shortly after which the results are returned to the user through the plugin.
Minimizing risk in our process
Potentially sensitive interactions between OpenAI and your data are restricted to a limited set of transactions on an as-needed basis. Further, we limit these interactions to those necessary to fulfill an end user’s request.
Data isolation: Protecting customer information
We achieve data isolation through a multi-tenant architecture:
- Dynamic data referencing: Customer data is referenced at runtime in response to specific requests, with access scope determined by user credentials.
- No fine-tuning: We use off-the-shelf AI models without integrating customer data.
- Strict data usage policies: We never incorporate customer data in training datasets, and our agreements with OpenAI explicitly prohibit such use. For more details, please see OpenAI’s Enterprise Privacy page.
Ensuring data security
Our approach includes robust security measures: infrastructure protections that are designed to prevent unauthorized access and mitigate cyberattacks. Please see the WordPress VIP security policy documentation for details.
Safeguarding confidentiality
We safeguard the confidentiality of customer data through a variety of measures including the following:
- Explicit Authorization: Users must expressly opt into the use of tools that involve the sharing of their data with our AI service provider.
- Minimal Data Exposure: Our system processes only the necessary information. For instance, when referencing a 10,000-word article, we only share a brief excerpt with AI models.
- Contractual Safeguards: Contracts strictly prohibit third-party use of customer data for training or other unauthorized purposes.
Last updated: July 07, 2025